When companies move into the cloud, the thought normally is that cloud will be much cheaper than dealing with on premise Data Centers, Management etc. While much of this can be correct in terms of manageability many enterprises get caught in the same predicament of treating there cloud infrastructure as just a virtual data center. Unless making the cloud paradigm shift and building for elasticity vs a lift and shift approach many enterprises find themselves spending more than they initially forecasted or planned for. Luckily there are some good approaches that can help and where you can see some vast improvement.
With a company’s journey to the cloud it is imperative that you truly treat the cloud as what it is, a Platform as a Service. This will not be the same like your SaaS offerings where you just sign up, pay your monthly or annual subscription and just forget about it. You will need a team that is dedicated to having a holistic overview and a unique approach to ensure your cloud platforms are running proficiently and as expected. They will need to be proactive and be able to engage with the business on a daily or weekly basis to see where cost optimizations can take place. If you do not have a team such as this already then the suggestion would be to start small with a couple of people and grow as necessary. Some skills to look for would include the following:
AWS best practice has obviously changed over the years since the inception of EC2 and what was considered “Classic” EC2. When Classic EC2 first came around there was no concept of VPC so segregation of your compute environment, it was really down to account level. The concept was simple, Production, Development, QA and Staging all lived in separate accounts. Once EC2 moved into present day with the onset of VPC’s, we had the ability to create not only a logical separation but a network one as well. This moved best practice from each environment living into its own account to each environment living with-in the same account since we can create up to 5 VPC’s in the in the same region. Once Organizations was announced best practice has once again gone back to a multiple account approach to deal with each environment as from and IAM access management perspective it is easier to just allow access via account level vs writing complex IAM policies to limit access to a particular VPC environment. Since you do not pay per account but pay per resource that is used the cost still equates to be the same. With either topology segregation, the important thing to stick to is ensuring that your environments are segregated. You will see how this will benefit you as we move forward.
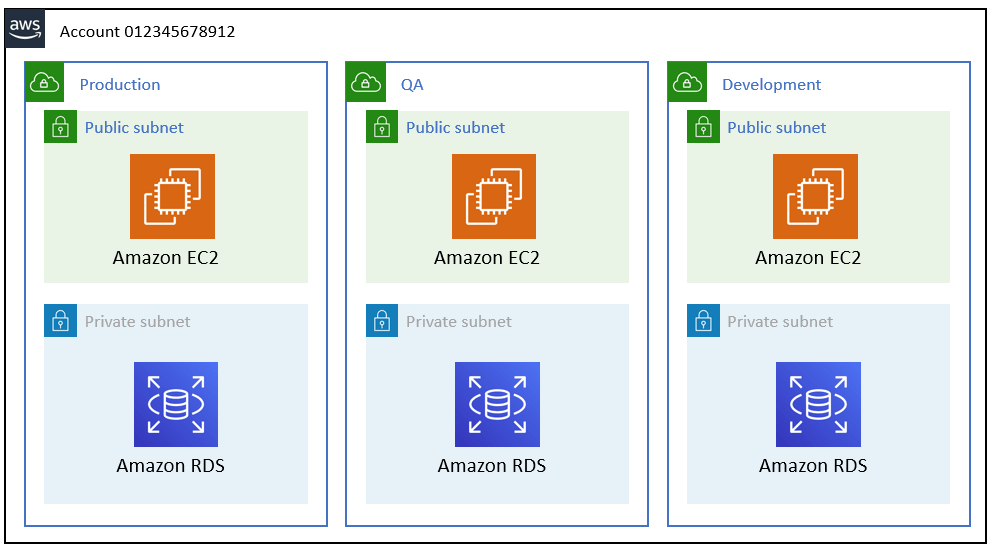
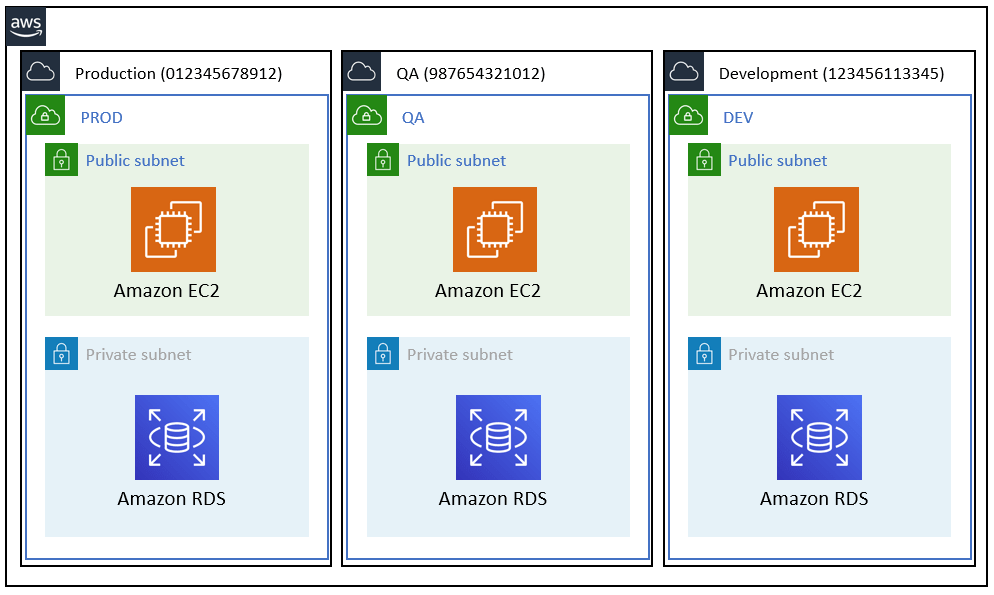
In order to understand what, why and where you are spending money on resources, it is important to come up with a good tagging strategy. There are some good articles around the web that discuss in greater detail what the tagging strategy should look like so for that reason we will not go to in depth but just make note whatever your tagging strategy is it is imperative that you stick to it across all of your resources. We will however point out what we feel are a must in order to be cost effective:
With having a tagging strategy in place it is important to ensure the tagging strategy is strictly followed. We would recommend following an automated resource tagging strategy where ever possible as this takes away human error.
In a traditional enterprise, you have your self-hosted Data Center and when something is deployed there it just stays up and running at all time. With moving to the cloud it is no wonder that mentality continues and AWS is used as an extension of the on premise Data Center. You need to treat your AWS infrastructure more like your home office, when systems are not in use turn them off. With leveraging an Asset Tagging Strategy anything that is not considered Production should be turned off at the end of each business day. Take for example running an m5.xlarge EC2 Instance in us-east-1 region. When running this instance On-Demand your monthly cost for this instance would be $140.16 when the instance is running for 24 hours a day. Now if you look at that same EC2 Instance running for 12 hours a day excluding weekends your monthly cost has now decreased to $50.11 or a 64% savings. If tags are in place you can allow CloudWatch and Lambda to schedule and execute the shutdown for you.
Understanding your workload and what it requires to properly work is vital. Many organizations struggle with right sizing. Ensure that any instances that you are running is using the latest generation of a family as the latest version of a family is less expensive than its predecessor and has higher performance for the same size. When having an instance over provisioned even by just one size, the rate can be more than double for that instance. Look to CloudWatch Metrics on your EC2 Instances to get an idea what has a low CPU utilization factor. AWS recommends that that the CPU Usage should go above 40% during a given time frame.
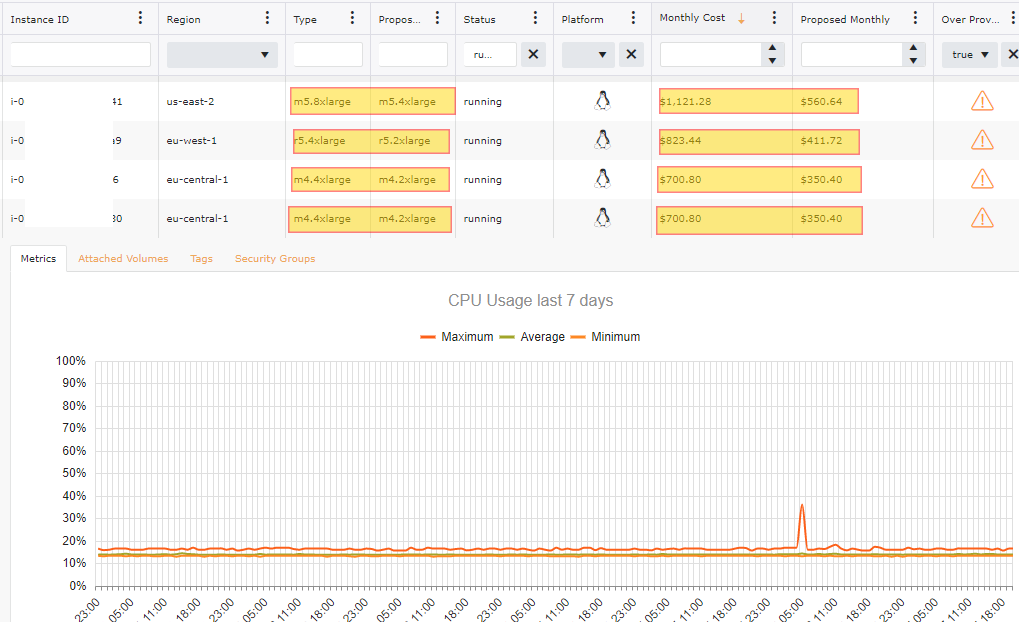
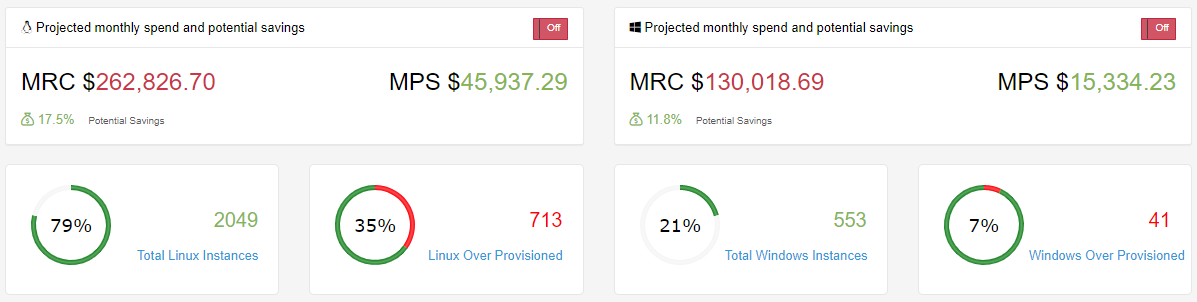
Just having a few of over provisioned instances with-in your accounts can still lead to a drastic price difference. In the image below this particular collection spans over 200 AWS Accounts and out of the 600 +/- Windows Instances 7% are over provisioned. When the 41 Instances are addressed it will be an 11.8% savings or just over $15,000 a month in reduced cost related to Windows EC2 Instances.
When using EC2 Instances or RDS Instances, organizations overlook that there is a cost associated with the EBS Volumes and you are paying for those volumes regardless if your EC2 Instance or RDS Instance is running or not. If you have an Instance that has been powered down then consider taking a Snapshot of the Volume and then deleting the Instance. If you need to restore the machine at any point in the future this can be done by just restoring the Snapshot. Of course it goes without saying that a well-defined Tagging Strategy is important here. A snapshot will only consist of the data that makes up the used portion of the volume. Let’s say you have 100GB volume that only has 10GB of space used. With an EBS Volume you are paying for all 100GB which will cost $10.00 per month whereas a Snapshot is charged $0.05 per GB stored. This would reduce your cost for this EBS Volume from $10.00 a month to $0.25 per month.

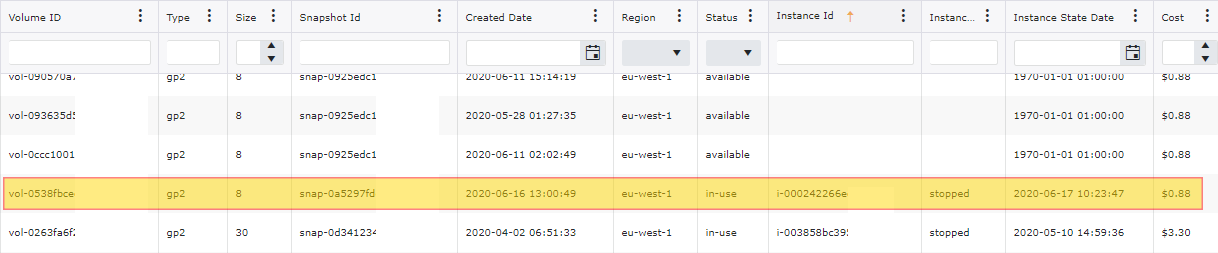
You can use the AWS Console and navigate to EBS Volumes in order to see what volumes are in an available state. In order to see what volumes are attached to EC2 Instances that are in a stopped state. An alternative approach would be to use the use the aws-cli to query for EC2 Instances that are in a stopped state. You can run the following command in order to find these instances and volumes:
aws ec2 describe-instances --filters Name=instance-state-name,Values=stopped
{
"Groups": [],
"Instances": [
{
"AmiLaunchIndex": 0,
"ImageId": "ami-aabbcc2342aa",
"InstanceId": "i-aabbcc2342aa",
"InstanceType": "t2.micro",
"KeyName": "PrivateKey",
"LaunchTime": "2020-02-26T18:33:54.000Z",
"Monitoring": {
"State": "disabled"
},
"Placement": {
"AvailabilityZone": "eu-west-1a",
"GroupName": "",
"Tenancy": "default"
},
"Platform": "windows",
"PrivateDnsName": "ip-192-168-0-19.eu-west-1.compute.internal",
"PrivateIpAddress": "192.168.0.19",
"ProductCodes": [],
"PublicDnsName": "",
"State": {
"Code": 80,
"Name": "stopped"
},
"StateTransitionReason": "User initiated (2020-06-17 08:23:47 GMT)",
"SubnetId": "subnet-aabb34cd",
"VpcId": "vpc-26cc2640",
"Architecture": "x86_64",
"BlockDeviceMappings": [
{
"DeviceName": "/dev/sda1",
"Ebs": {
"AttachTime": "2020-02-23T21:15:42.000Z",
"DeleteOnTermination": true,
"Status": "attached",
"VolumeId": "vol-aabbccdd1234567"
}
}
],
"ClientToken": "",
"EbsOptimized": false,
"EnaSupport": true,
"Hypervisor": "xen",
"IamInstanceProfile": {
"Arn": "arn:aws:iam::012345678901:instance-profile/EC2Default",
"Id": "AIPAJHFBV3YCY3YFZZO4W"
},
"NetworkInterfaces": [
{
"Attachment": {
"AttachTime": "2020-02-23T21:15:41.000Z",
"AttachmentId": "eni-attach-01321abdfaa",
"DeleteOnTermination": true,
"DeviceIndex": 0,
"Status": "attached"
},
"Description": "Primary network interface",
"Groups": [
{
"GroupName": "Consumer-Private",
"GroupId": "sg-111133sa"
}
],
"Ipv6Addresses": [],
"MacAddress": "0a:00:11:ab:ba:c1",
"NetworkInterfaceId": "eni-aabbccdd123",
"OwnerId": "012345678901",
"PrivateIpAddress": "192.168.0.19",
"PrivateIpAddresses": [
{
"Primary": true,
"PrivateIpAddress": "192.168.0.19"
}
],
"SourceDestCheck": true,
"Status": "in-use",
"SubnetId": "subnet-ec89dab7",
"VpcId": "vpc-26cc2640",
"InterfaceType": "interface"
}
],
"RootDeviceName": "/dev/sda1",
"RootDeviceType": "ebs",
"SecurityGroups": [
{
"GroupName": "default",
"GroupId": "sg-116a6b6a"
}
],
"SourceDestCheck": true,
"StateReason": {
"Code": "Client.UserInitiatedShutdown",
"Message": "Client.UserInitiatedShutdown: User initiated shutdown"
},
"Tags": [
{
"Key": "Name",
"Value": "ExampleInstance"
},
{
"Key": "Department",
"Value": "Consumer"
},
{
"Key": "Environment",
"Value": "DEV"
},
{
"Key": "CreationDate",
"Value": "2020-02-23T21:15:42.000Z"
}
],
"VirtualizationType": "hvm",
"CpuOptions": {
"CoreCount": 1,
"ThreadsPerCore": 1
},
"CapacityReservationSpecification": {
"CapacityReservationPreference": "open"
},
"HibernationOptions": {
"Configured": false
}
}
],
"OwnerId": "012345678901",
"ReservationId": "r-000123aabbcc"
}
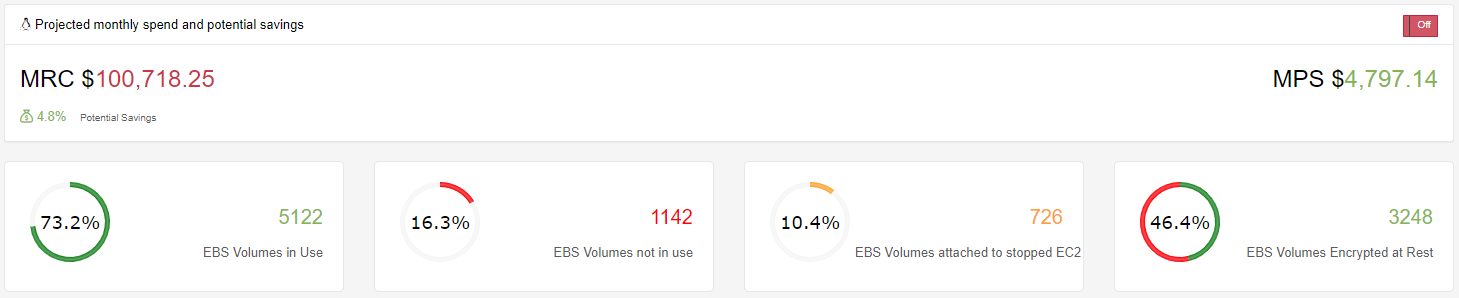
Looking at just over 200+ accounts, you will see that this seems to be a common occurrence. 16.8% of the volumes that we are paying are not attached to any EC2 Instance and would be a good candidate for deletion or to Snapshot before deleting. This would reduce our monthly EBS Volume by 4.8% or almost $5,000 per month.
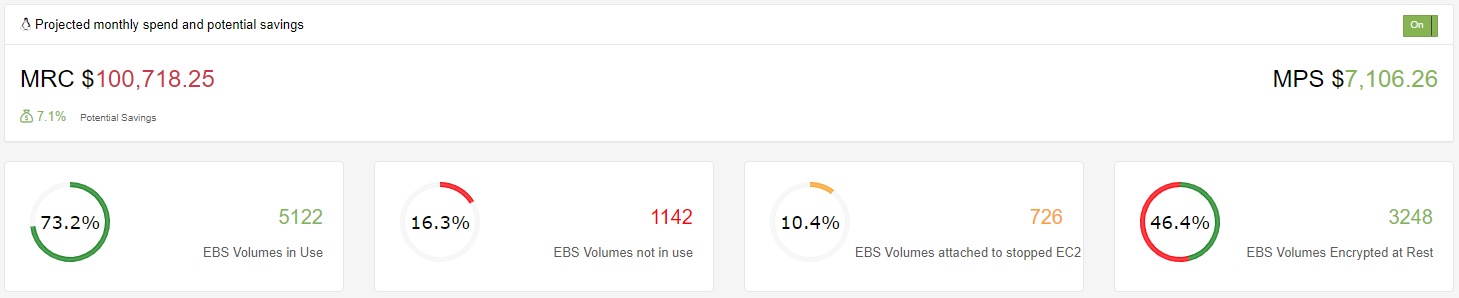
If we include the 10.4% EBS Volumes that are attached to EC2 Instances that are in a stopped state then we can further reduce the monthly spend by an additional 3.3% bringing the total monthly reduction to just over $7,000.
Knowing your compute pattern and your usability, it is important to have a reserved instance strategy. With IntelligentDiscovery.io our strategy is based on a quarterly basis as we know that we will see fluctuation in instance usage based on customers we are serving at any given time. A reservation is mostly a financial tool, you commit to pay for resources during 1 or 3 years and get a discount over the on-demand price. Managing reservations is a time consuming task as it requires not only looking at current billing and usage, but working with the business or account user (if working in multiple accounts) to understand what the current consumption and usage will look in the future. This is where a strong tagging strategy as well as the Cloud Center of Excellence should play key roles. We only base our Reserved Instances on anything that we have tagged as Production as we strictly rely on our Lights Out strategy to ensure we are not waisting money on other environments.
Reserved instances come in a couple different options, there are Standard or Convertible options. Payment options come with three choices: Full Upfront, Partial Upfront, and No Upfront. With partial and no upfront, you pay the remaining balance monthly over the term. We prefer partial upfront since the discount rate is really close to the full upfront one (e.g. 40% vs 41% for a standard 1-year term with partial).
Here we have flagged instances that should be converted to a Reserved Instance.

This image below first shows just the cost optimization that can take place based off of over provisioned EC2 Instances. If we take into account our recommendation on EC2 Reserved Instances you can see the cost savings almost doubles for both Windows and Linux systems.


RDS should be treated in very much the same way as EC2 instances. We can look at the CPU Utilization of the RDS instance and validate if we have over provisioned the database and look to resize accordingly. Many times RDS Instances are overlooked. Even when it is known that an instance is over provisioned, many enterprises are reluctant to downsize as it will require a scheduled downtime in order to make the instance type change.
To help you understand if your instance is overprovisioned you can look at the metrics directly in the AWS Console for your RDS Instance under the metrics tab. You will notice that going down one size with-in the same family is about half of your current cost.
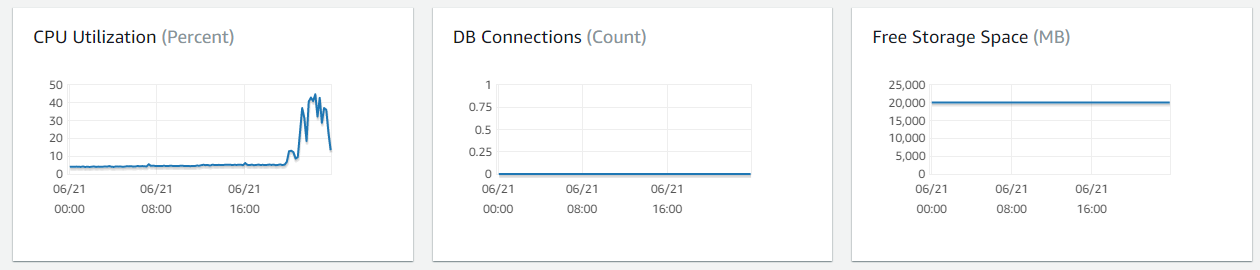
Look for any Database that are not being used. We can validate this by looking at Database connections for the past 30 days. The Cloud Center of Excellence should work directly with the account owner / user to determine the purpose of the database and if it can be terminated.
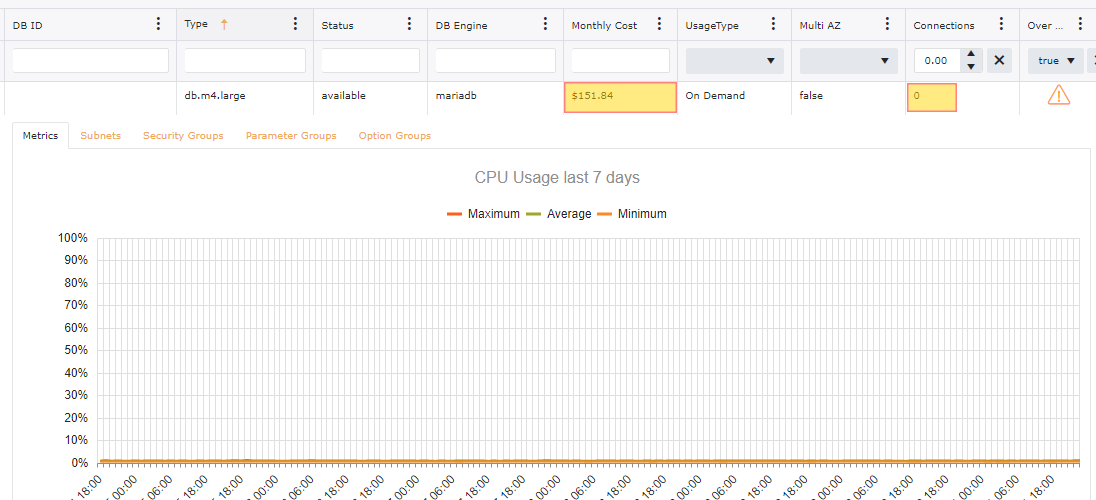
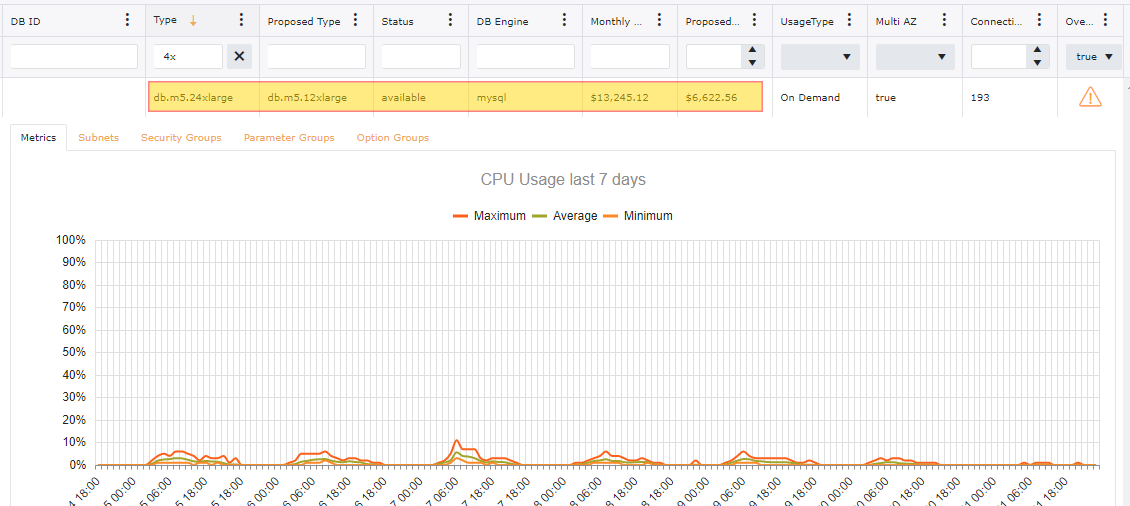
With having over provisioned instances with-in your accounts can still lead to a drastic price difference. In the image below this particular collection spans over 200 AWS Accounts. With just looking at saving potential on Over Provisioned there is an opportunity for a 20% reduction in monthly spend.
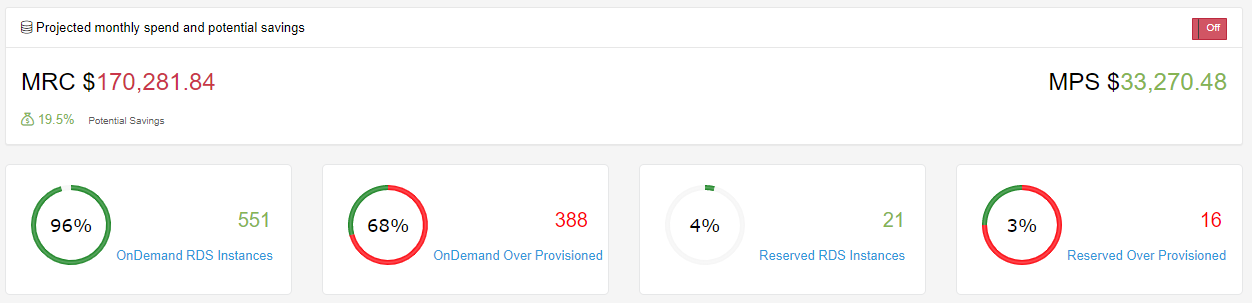
We take a similar approach in relation to RDS Reserved Instances as we do with EC2. There are some slight changes to our approach as we find that once we have a Database tagged as Production, we are less likely to want to take this down and deal with Instance changes. Also having a production database is normally understood from day one so we start looking at Reservations once the Uptime of a production server has hit 30 Days. We do this on Database engines that support the Normalization Factor. These engines include: MySQL, MariaDB, PostgreSQL, Aurora MySQL and Aurora PostgreSQL. We tend to take the Partial Upfront for 3 years as our hope is our customers and in turn our Database Usage will be valid for the 3 years. Looking at a MySQL RDS offering for 3 years we can realize a 59% savings over the On Demand cost.
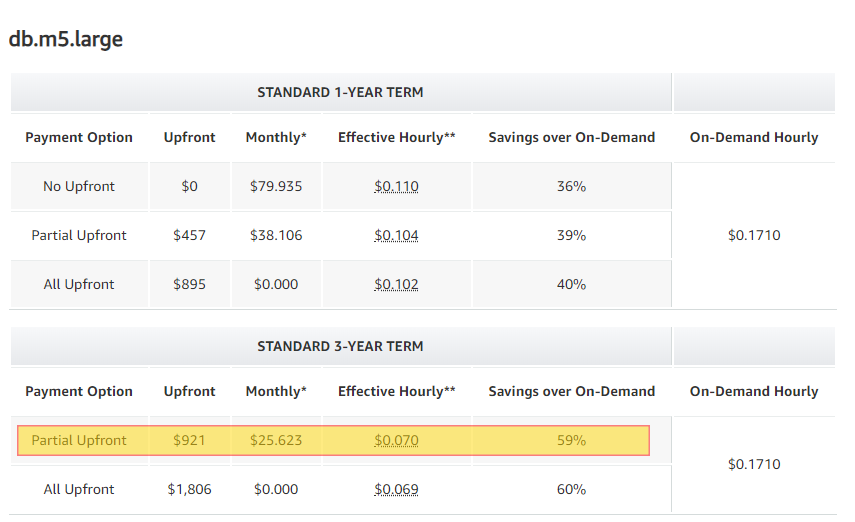
For Database engines that do not support Normalization Factor we look at the 90 day term before making a Reservation suggestion. MSSQL and Oracle do not support this model, nor is there a concept of Standard vs Convertible Reserved Instances in RDS so we go with a 1 year term partial upfront payment.
You can see that adding in Reserved Instances for RDS can offer a significant savings in the example below. The first image is just savings with correct Database sizing suggestions whereas the second image shows the cost reduction with Reserved Instances suggested.


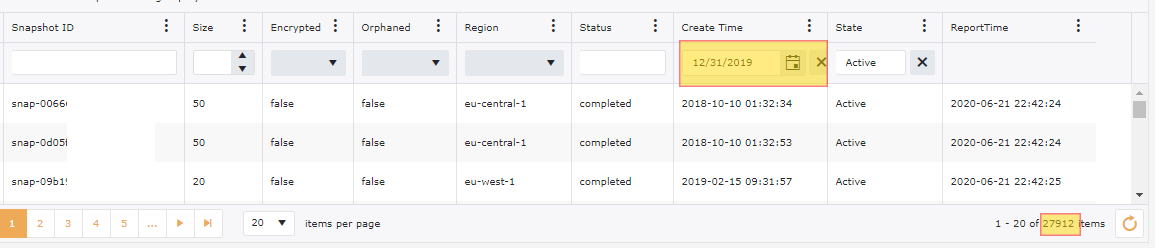
Snapshots seem to pile up over time and rarely seem to get purged when an instance gets terminated. Look to clean up any un-needed to snapshots or orphaned snapshots. Even though snapshots are relatively inexpensive when comparing to housed EBS volumes, when having a significant amount of these the price can start to adding up. Unfortunately there is not a precise way of seeing exactly how much each snapshot is costing you as snapshots are stored with AWS Managed account specific for S3 so we do not have access to get an idea of truly how much space our snapshot is actually using. Regardless good hygiene would be to remove old outdated snapshots. Going back to our Tagging Strategy it would be good to create a tag for DeleteAfter specifying a specific date. Create a lambda function that can go through on a daily bases and delete anything after this tagging. This is a good approach for moving forward, however how do you deal with the clutter that has piled up until this point? The best option is to validate if this is an Orphaned snapshot. You will want to do this in the following way:
aws ec2 describe-snapshots --owner-ids YOUR-ACCOUNT-ID
You have received vol-ffffffff for the VolumeId, this volume has been deleted and thus this snapshot if Orphaned.
{
"Description": "backup of volume",
"Encrypted": false,
"OwnerId": "012345678912",
"Progress": "100%",
"SnapshotId": "snap-02681db9ad59efe52",
"StartTime": "2017-03-11T17:51:53.000Z",
"State": "completed",
"VolumeId": "vol-ffffffff",
"VolumeSize": 8
}
If you recieve a valid VolumeID and you do not have Created or Copied in the Description, then you will need to run "aws ec2 describe-volumes" and validate if this VolumeId exists
{
"Description": "Automated backup",
"Encrypted": false,
"OwnerId": "012345678912",
"Progress": "100%",
"SnapshotId": "snap-07c9401ad10fe779c",
"StartTime": "2016-12-21T15:21:45.000Z",
"State": "completed",
"VolumeId": "vol-0478cdc5b105697e6",
"VolumeSize": 8
}
If you recieve a valid VolumeId or have Created in the Description you will need to look the InstanceId, AmiId and the VolumeId to validate if any of those exist. If none of these exist, then this is an Orphaned Snapshot, then you will need to run "aws ec2 describe-volumes" and validate if this VolumeId exists
{
"Description": "Created by CreateImage(i-07e293654ef9277af) for ami-099b112fe816f9e70 from vol-095100984fcfa9b27",
"Encrypted": false,
"OwnerId": "012345678912",
"Progress": "100%",
"SnapshotId": "snap-0f158f4ddcdaa5e84",
"StartTime": "2018-05-30T14:50:55.000Z",
"State": "completed",
"VolumeId": "vol-095100984fcfa9b27",
"VolumeSize": 20
}
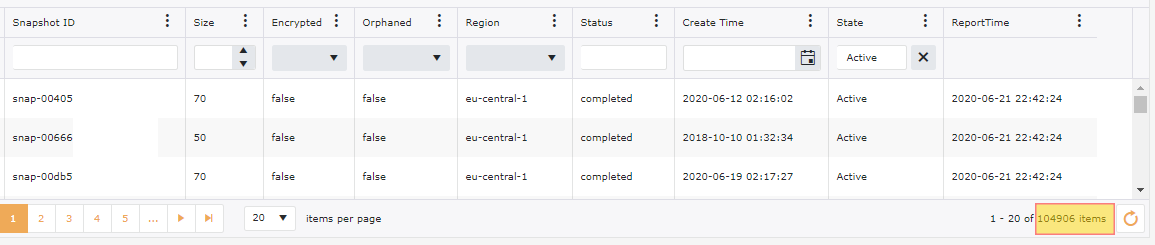
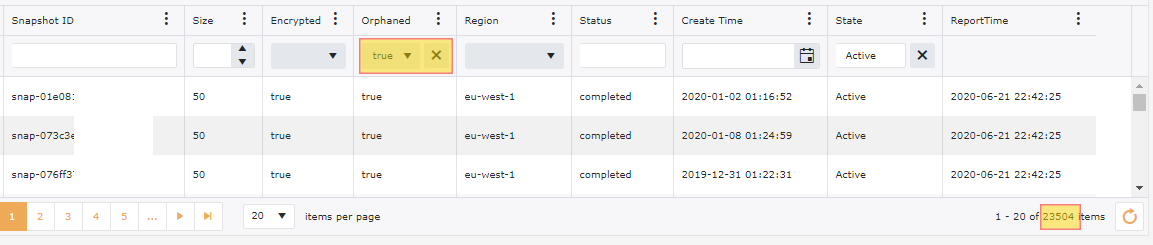
Snapshots tend to gather at a huge rate. Continuing with our examples of our 200+ accounts, we have 100,000+ snapshots, however out of these we have 20,000+ snapshots that are Orphaned or not related to anything. We have also done a filter on these snapshots for anything older than 6 months and we have an additional 25,000+ Snapshots that could be targeted for deletion.
By default just about every service that you use with-in AWS will log directly to a CloudWatch Log Group. This is great for troubleshooting and security requirements, however the default setting for log retention expiration is set to Never, meaning AWS will keep these logs indefinitely. Depending on how verbose your logs are, the cost can be somewhat minimal when looking at your entire account as a whole, however this is still a good practice to keep only what is truly needed for a specified time frame and only log what you truly need to log. Take for instance Lambda. The more verbose your function is, the more data that will be written to your CloudWatch Log. You will pay an ingestion rate for those logs that is considerably more compared to the storage cost of the log. The longer your function has been up and running the greater amount of data that is being stored in S3 for this log if you are not periodically cleaning. Look at what your corporate policy is for log retention for each of your environments and adjust your CloudWatch Log Group’s retention accordingly. Many organizations look to offload most of their logs into ELK or SPLUNK. If this is the case, then cloud watch log retention could then be further reduced.
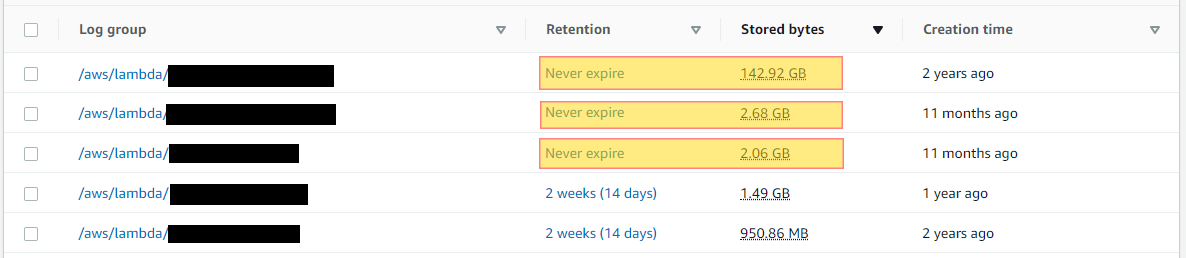
In the below example you can see these 2 highlighted logs are ingesting a considerable amount of data as well as storing. At the time of writing this article these logs are relatively new, however the retention is set to never expire. Looking at the first log in this example, we have almost a 3 TB ingestion rate per month which in turn will be stored indefinitely. In the region ap-northeast-1 we have a storage cost of .033 per GB. If this log is not monitored and cleaned from time to time, the cost can rapidly start to grow. Continuing along the data ingestion trajectory would add $92.70 per month each month. For example the project storage cost for this log by the end of 1 year would be up to $1,112.40.

Here we have laid out some simple steps that can be taken to have a drastic impact on cost with your AWS monthly spend. It is important to keep in mind, especially in an enterprise that Cost Optimization is not just a onetime thing. In order to maximize your cost reduction it will require proactive monitoring as well as the paradigm shift in mentality from an On Premise Data Center to a true cloud native approach. By implementing some of the approaches that have been listed above you can see significant reduction in your monthly spend.
Are you curious as to what type of data Intelligent Discovery collects in relation to AWS vulnerabilities?
Login into our on-line demo to see a simulated view of what Intelligent Discovery collects and explains how to remediate.
demo.intelligentdiscovery.io
LDAPTIVE, LLC 2018 © All Rights Reserved. Privacy Policy | Terms of Service